
We are currently living through the greatest explosion of productivity in the history of software engineering.
With the maturation of advanced developer copilots and autonomous coding agents, writing code has become practically free. A junior developer can spin up a microservice in an afternoon. UIs are generated in seconds. Boilerplate has evaporated.
CTOs and engineering leaders are celebrating this massive velocity boost. But we are optimizing for the wrong bottleneck.
We have spent decades treating writing code as the primary constraint of software development. In reality, the lifetime cost of software is not in authoring the code; it is in reading, understanding, maintaining, and refactoring it.
By making code generation instantaneous, we have opened a firehose of raw syntax. The result is the rise of a new and highly dangerous organizational liability: AI Legacy Debt.
This is the silent accumulation of vast, syntactically correct, test-passing codebases that no single human inside the organization actually understands, designs, or owns. And if we do not change how we architect our engineering systems today, this debt will paralyze enterprise software within the next three years.
Why AI-generated debt is fundamentally different
Traditional technical debt is an intentional or highly understood trade-off. A human developer says: “We are going to hardcode this integration to hit the Q3 deadline, and we’ll refactor it into a proper abstraction in Q4.” It is documented in Jira, stored in developer memories, and bounded by human limitations.
AI Legacy Debt is silent, alien, and conceptually hollow. It manifests in three distinct ways:
1. The Loss of the Conceptual Anchor
When a human writes code, they build a mental model of why the code is structured a certain way. They understand the edge cases they struggled with, the architectural patterns they chose, and the underlying business logic.
When a developer uses a copilot to generate 150 lines of code, they often review it, see that the unit tests pass, and merge it. The code is syntactically perfect. It works. But the conceptual anchor—the deep, human understanding of why those specific lines exist—never enters anyone’s brain. The code is conceptually hollow.
2. The Hallucinated Architecture
Generative models do not design architectures; they predict the next most likely token. When an LLM generates code across a repository, it does not hold a coherent, long-term vision of your system design.
Over months of agentic contributions, a codebase becomes a patchwork of inconsistent patterns: three different ways to handle state, redundant helper functions scattered across files, and subtle logical duplications. It behaves like a Frankenstein monster—stitched together perfectly at the seams, but lacking a unified soul.
3. The Cognitive Load Tsunami
Traditional debugging relies on familiarity. When a system breaks at 2:00 AM, a senior engineer can reason about the failure because they understand the codebase’s patterns.
When a system built on AI Legacy Debt breaks, engineers must debug an unfamiliar, verbose codebase written by a machine. The cognitive load required to read and comprehend machine-authored code under pressure is significantly higher than debugging code written by human peers. The “time to resolution” skyrockets, wiping out any initial velocity gains.
The Paradigm Shift: From Typist to Editor
For fifty years, the limiting factor in software engineering was typing speed, syntax mastery, and compiler errors. Today, those limits have collapsed.
The new bottleneck is cognitive bandwidth. Software engineering has transitioned from a writing-first discipline to a comprehension-first discipline.
| Dimension | The Classical Era (Writing-First) | The AI-Native Era (Comprehension-First) |
|---|---|---|
| Primary Limitation | Developer hours, syntax fluency, and typing speed. | Human cognitive bandwidth, attention span, and verification speed. |
| Core Engineering Skill | Authoring clean syntax, manual debugging, and algorithmic design. | Specifying architectural intent, critical reading, and automated verification. |
| Primary Metric | Velocity, Story Points, Lines of Code shipped. | System Simplicity, Change Failure Rate, Time to Comprehend. |
| Lifetime Cost Driver | Implementation and authoring complexity. | Verification, alignment auditing, and legacy maintenance. |
| Risk Profile | Slow time-to-market, manual bugs. | Code bloating, architectural drift, and system-wide incomprehensibility. |
Three Rules for Architecting Against AI Bloat
To survive the code tsunami, CTOs must abandon legacy management practices and architect their development lifecycles to aggressively defend against code bloat.
Rule 1: Enforce Strict Declarative Boundaries
If AI agents are going to generate your implementation, you must severely restrict their freedom to design interfaces.
CTOs must enforce strict, contract-driven architectures. Every module, service, and function must have rigidly defined schemas, strict typing, and immutable boundaries.
- Use OpenAPI, Protobuf, or strict TypeScript types to define how data moves.
- Never allow an AI copilot to bridge systems using ad-hoc, untyped JSON objects.
- Treat the interface as the human-designed contract, and let the AI fill in the implementation inside a sandboxed container.
Rule 2: Prioritize “Readability” Over “Write-ability”
LLMs love verbosity. They will happily write 200 lines of boilerplate to solve a problem that a elegant, high-level abstraction could solve in 10 lines. Because writing is free, we tolerate the bloat.
You must aggressively fight this tendency.
- Set strict code-size limits and complexity budgets on pull requests.
- Configure linters to flag verbose, repetitive patterns.
- If a copilot generates a sprawling function, force the developer to instruct the LLM to: “Rewrite this to be as concise, declarative, and readable as possible.”
- Remember: Code is a liability, not an asset. The less code you have to represent a feature, the lower your legacy debt.
Rule 3: Build an Automated Refactoring Loop
You cannot fight machine-scale code generation with manual human review. You need to deploy machines to clean up after machines.
CTOs must integrate Continuous Refactoring Agents into their CI/CD pipelines. These are specialized AI agents whose sole job is to:
- Scan the repository for redundant utility functions and merge them.
- Identify architectural drift and refactor code to align with your core design system.
- Automatically generate up-to-date visual architectural maps and dependency graphs of the codebase.
- Flag “dead code” and generate PRs to delete it.
If your code generation pipeline does not have an equal and opposite code-deletion and cleanup pipeline, your codebase will collapse under its own weight.
Team Topologies: The “Orchestrator” Model
This shift fundamentally alters how we structure engineering teams. The traditional hierarchy of junior, mid, and senior developers typing code in parallel is failing.
Instead, we must transition to the Orchestrator Model:
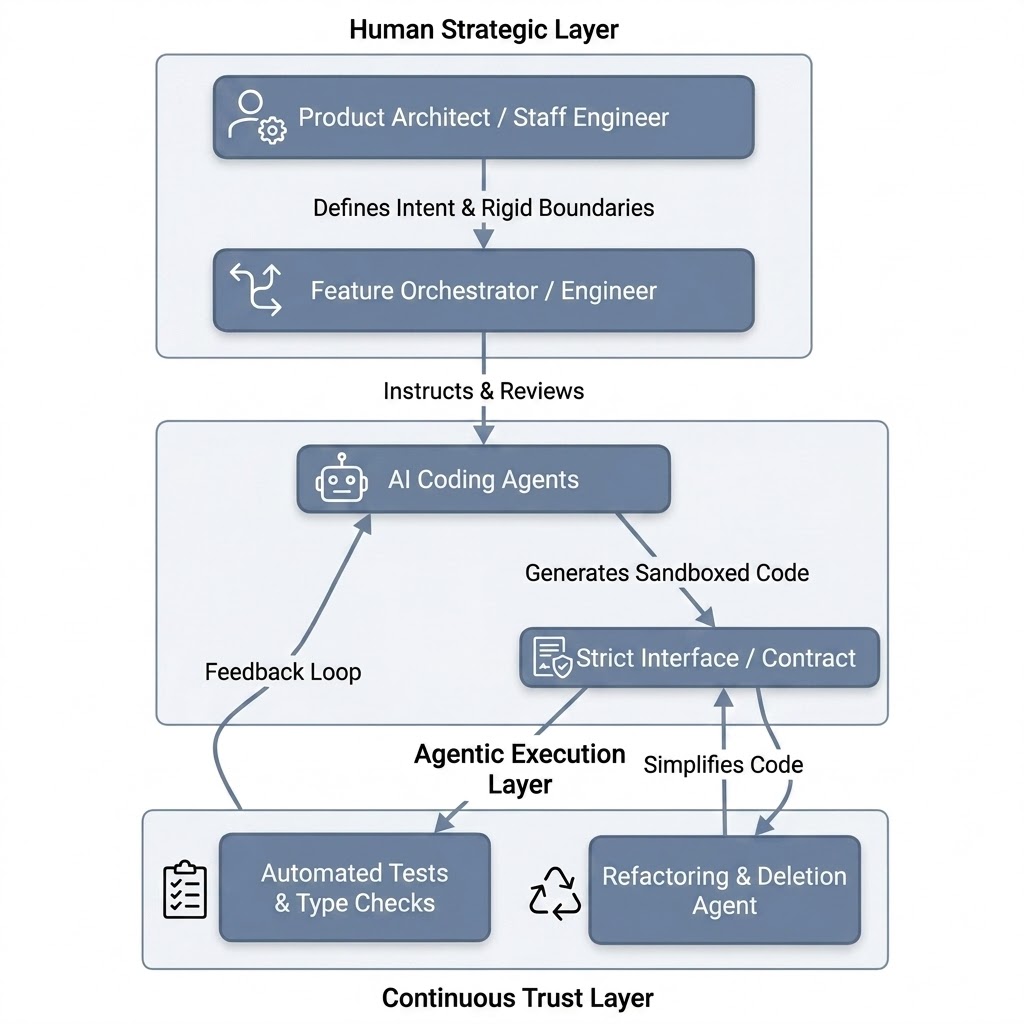
In this model, the roles are sharply defined:
- The Product Architect / Staff Engineer: Designs the macro-system, sets the strict API contracts, and defines the guardrails. They own the “what” and the “why.”
- The Feature Orchestrator (formerly the Software Engineer): Acts as a high-judgment editor. They write highly precise prompts, review the generated implementations for architectural alignment, and orchestrate the agents. They do not write boilerplate; they verify intent.
- The Coding Agents: Execute the micro-tasks within the strict boundaries defined by the architect. They write the tests, fill in the implementation details, and handle the syntax.
The Uncomfortable Truth for CTOs in 2026
Velocity is a vanity metric.
If your engineering team is bragging about shipping 10x more features and code than they did two years ago, they are likely building a mountain of AI Legacy Debt that will eventually grind your organization to a halt.
In the AI-native era, the companies that win will not be the ones that wrote the most code. The winners will be the organizations that maintained the tightest, most elegant, most decoupled, and most comprehensible systems.
Your primary job as a technology leader is no longer to help your team write code faster. It is to build a culture, an architecture, and a pipeline that values comprehension over creation, and system simplicity over raw velocity.
The code tsunami is here. It is time to start building the levees.
*Are you measuring the cognitive load of your generated codebases? How is your team defending against AI Legacy Debt?
Comments
Have a question or a different perspective? Add a comment below.